☆ デュアルシステムとデュプレックスシステム
|
|
|
関連して、スタンバイ系
も覚えましょう。
(H12-1K-79)
(H11-1K-77)
(H10-1K-79)
|
|
デュアルシステム
|
同じ(オンライン)処理を2つのCPUで同時に実行する
|
ホットスタンバイ
|
|
デュプレックス
|
CPUは2つあるが、
1つはオンライン系として使用し、1個はバッチ系として使用する。
|
ウォームスタンバイ
コールドスタンバイ
|
☆ マルチプロセッサ(密結合と疎結合)(H11-1K-18)(H10-1K-77)
|
|
メモリ
|
OS
|
|
密結合
|
共有メモリ
|
単一のOS
|
|
疎結合
|
各プロセッサごとのメモリ
|
異なるOSも可
|
相対的に言うと、密結合は
・プロセッサの数に上限があります。(メモリなどを共有しているため)
・性能は、CPUの数に比例しません(一般的に√(CPU数)倍)
・キーワードは競合⇒ボトルネック
☆ RISC と CISC は省略
☆ パイプライン(H11-1K-11)
|
□
|
□
|
□
|
□
|
□
|
□
|
|
|
|
|
□
|
□
|
□
|
□
|
□
|
□
|
|
|
|
|
□
|
□
|
□
|
□
|
□
|
□
|
キーワードは、”ステージ”、”並列に動作”です。
☆ パイプラインを使う時と、使わない時ではどのくらい速度は違いますか? ☆
という問題が出されます。
(過去問より)
・各命令が5サイクル
・ストールなしで実行
・20命令で実行
で、パイプライン無しの時と比べて時間は?
|
[1]
|
[2]
|
[3]
|
[4]
|
[5]
|
|
|
|
|
|
|
|
|
|
[1]
|
[2]
|
[3]
|
[4]
|
[5]
|
|
|
|
|
|
|
|
|
|
|
|
|
・・・
|
・・・
|
・・・
|
|
|
|
|
|
|
|
|
|
|
|
|
[1]
|
[2]
|
[3]
|
[4]
|
[5]
|
で、完了。
|←ここから、勘定して、 ここまで→|
上のような絵で考えてみることをお勧めします。
・1回目は5単位。
・2回目は1単位足して、6単位。
こんな感じで、1ずらすのは20-1=19回。
つまり、5+1×19=24単位。
パイプラインを使わなかったら、
5×20=100単位。
24%に短縮されます。
この問題は出来るようにしておきましょう。 |
☆ スーパースカラ(H11-1K-18)
処理UNITが複数あります。
|
[1]
|
[2]
|
[3]
|
[4]
|
[5]
|
|
[1]
|
[2]
|
[3]
|
[4]
|
[5]
|
複数あるから、重ねられます。
☆ パイプラインハザード
パイプラインに関連して・・・
”パイプラインハザード”という言葉があります。
きれいにプログラムが流れようとするけど、流れない状態のことを言います。
|
|
+-
|
データハザード
|
・・・以前の命令の結果を使う
|
|
--
|
-+-
|
制御ハザード
|
・・・Jump命令
|
|
|
+-
|
構造的ハザード
|
・・・リソースの競合
|
|
命令
|
命令の例
|
|
[1]
|
取り出し
|
|
[2]
|
解釈
|
|
[3]
|
・・・
|
|
[4]
|
・・・
|
|
[5]
|
・・・
|
[1](命令を取り出し)が終わったら、[2](解釈)してる間に次の人が[1](取り出せる)じゃない?
というのが、パイプラインの考えでした。
☆ データハザード~以前の命令の結果~
例えば、アセンブラの命令
|
ADD R1,R2、R3 ・・・ R2+R3をして、R1に入れる
SUB R4,R1、R5 ・・・ R1-R5をして、R4に入れる
|
を実行するとします。
ADD命令でR1にR2+R3の結果を入れるのは、[1]~[5]の一番最後です。
逆に、SUB命令でR1を取り出すのは、ADD命令でR1に計算結果を入れる前です。
これで、うまくいかなければ、エラーが出ます。
☆ 制御ハザード~Jump命令~
例えば、3の命令で、8にジャンプするとしましょう。
3を読み終わって、パイプラインで次に4、5と読んでいるのに、
あとから8にジャンプすることが分かったら、4、5を読んだことが、
無駄になるし、流れが乱れてしまいます。
このように、パイプラインが止まることを、”パイプラインストール”とか、”インターロック”とか言います。
用語として覚えておいて下さい。
☆ キャッシュメモリ(キーワード集)(H11-1K-18)(H10-1K-16)
・NFP
・ヒット率
・ライトスルー/ライトバック
・セットアソシエイティブ
キャッシュメモリ1に対して、主メモリがあるセットで対応。
試験に良く出るのがこれ。
・フルアソシエイティブ
キャッシュメモリ1に対して、主メモリはどこを使っても良い。
若干スピードが遅い。
・ダイレクトアソシエイティブ
キャッシュメモリ1に対して、主メモリ1で対応。
柔軟性がないぶん、速い。
・メモリインタリーブ・・・主記憶をバンクに分ける(バンクといえば、インタリーブ!)
・DMA
CPUを介さずに、
主記憶⇔入出力装置
をアクセスすること。
・RAID0~5(H12-1K-17)(H10-1K-18)
|
RAID 0
|
ストライピング
|
|
|
RAID 1
|
二重化
|
|
|
RAID 2
|
ハミングコード
|
}ほとんど使われていない
|
|
RAID 3
|
パリティ(バイト)
|
|
RAID 4
|
パリティ(ブロック)
|
|
|
RAID 5
|
パリティ+ストライピング
|
|
RAID 0(ストライピング)
ストライプ・・・帯です。
|
|
ディスク
A
|
ディスク
B
|
ディスク
C
|
|
|
『
|
『
|
『
|
|
→
|
1
|
2
|
3
|
|
→
|
4
|
5
|
6
|
|
→
|
7
|
8
|
9
|
|
|
』
|
』
|
』
|
バスに比べて、ディスクって遅いですよね?
1を読んでる間に、2を読みにいけば、少しでも早くなるでしょ?
RAIDというのは、冗長度を上げる(信頼性を上げる)ことです。
ストライプだけでは、例えば、”5”が無くなれば、全部だめになってしまいます。
→冗長性がありません。
RAID 2(ハミングコード)
”(7,4)ハミングコード”という書き方をします。
・4ビットのデータ、3ビットの冗長ビットがあります。
・7ビットでデータを保持します。
・2ビットの誤り検出、1ビットの誤り自動修正が出来ます。
RAID 3,4(パリティ)
|
ディスク
A
|
ディスク
B
|
ディスク
C
|
|
データ管理
|
データ管理
|
パリティ管理
|
このように、パリティ管理専用のディスクがあります。
この場合、ディスクCはパリティなので、アクセスが集中します。
RAID 5(パリティ+ストライピング)(H11-1K-16)
|
|
ディスク
A
|
ディスク
B
|
ディスク
C
|
|
|
『
|
『
|
『
|
|
→
|
1
|
パリティ
|
2
|
|
→
|
パリティ
|
3
|
4
|
|
→
|
5
|
6
|
パリティ
|
|
|
』
|
』
|
』
|
RAID 3、4の対策がRAID 5です。
それぞれに、パリティが散りばめられています。
RAIDのメインの目的は冗長性です。
RAID 0は冗長性がありません。目的は性能UPです。
☆ 性能評価尺度
この違いを言えるようにしておきましょう。
|
用語
|
説明
|
|
ターンアラウンドタイム
|
仕事を依頼してから、結果を得られるまでの時間(バッチ処理のイメージ)
|
|
レスポンスタイム
(応答時間)
|
『送信』キーを押下して、画面が次の1行目が表示されるまでの時間
(オンライン処理のイメージ)
|
|
スループット
|
一定時間に行える仕事量
|
☆ プロセスの状態遷移(H11-1K-18)
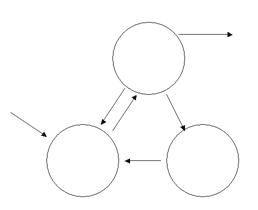
”○”の中の状態と矢印の意味が書けるようにしておきましょう。
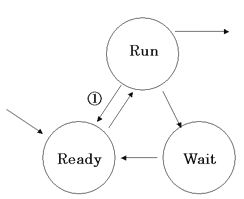
『①のイベント(Run→Ready)が発生する理由を2つ書きなさい。』という問題が出されたら?
・タイムスライスを使い切った(自分の持ち時間で終わらなかった)
・自分より優先順位の高いタスクがReady状態になった。
これに関連して、覚えておいた方がいいのが、
『最優先のタスクは「 」状態にとどまることが無い』です。
「 」には何が入るでしょう?
一瞬「Ready」状態になりますが、すぐにRun状態になります。
☆ プロセスとスレッド(H11-1K-18)
プロセスもスレッドもプログラムを実行する単位です。
|
|
プロセス
|
スレッド
(軽量プロセス)
|
|
メモリ
|
別
|
共有
|
|
|
スレッドを切り替える
オーバヘッドが大きい |
同一メモリなら、それほど
オーバヘッドは大きくない |
|
|
|
マルチスレッドは一般的
になっています。
|
☆ タスクスケジューリング(H11-1K-18)(H10-1K-23,24)(H10-1K-78)
タスクスケジューリングとは、たくさんの仕事をどういう風にやるか?です。
|
スケジュール名
|
説明
|
|
ラウンドロビン
|
一定時間おきに、チェンジ
|
|
到着順
|
タスクの到着順(世の中一般)
|
|
優先順
|
タスクに付けられた優先順
|
|
イベントドリブン
|
イベント(マウス押下、外線から着信)がトリガ(引き金)になってタスクが動く
|
|
多重待ち行列方式
|
例えば、 優先度 大、中、小に分けて、それぞれ待ち行列を作りましょうってイメージ
|
こういう過去問がよく出題されています。やっておきましょう。(H12-1K-21)(H11-1K-24)
以下のことに気をつけましょう。
☆優先順がついています。
☆I/Oについては、専用、共有の場合があります。
☆何を問われているのか?
☆図は丁寧に書きましょう。
☆ セマフォ
キーワードは排他制御
P操作・・・資源を使う。
V操作・・・資源を戻す。
電話ボックスをイメージしてください。だれかが使っていれば使えません。
係数セマフォというメモリがあって、P操作で-1、V操作で+1します。
それで、係数セマフォの値が0になると、資源が使えないことを意味します。
☆ 仮想記憶装置
主記憶装置 ≪ 補助記憶装置 なので、補助記憶装置を主記憶装置に見立てて使いましょう!ということです。
補助記憶装置から主記憶装置にロードする単位は3つありました。
|
単位
|
サイズ
|
|
|
プログラム単位
|
可変
|
ロールイン、ロールアウト
|
|
セグメント単位
(オーバレイ方式)
|
可変
|
|
|
ページ単位
|
固定
|
ページイン、ページアウト
|
ページイン、ページアウトを合わせて、”ページング”といいます。
そのページングにCPUの能力が削がれて、処理能力が上がらないことを”スラッシング”と言います。
主記憶にページが無いことを、”ページフォールト”と言います。無いから、ページインします。
一般論として、サイズの大きさは
です。主記憶にロードしてくる時に、空きが無ければページアウトします。
そのアルゴリズムが
|
{
|
FIFO・・・先入れ先出し
|
|
LRU・・・最も遅くに使用したページをページアウトします。
|
です。この手の問題が出題されても、図はていねいに書くことを心がけましょう。
このバッファ(メモリ)のやりとりについて。
オーバーヘッドは可変長の方が、固定長(ページ)よりも大きくなります。
☆ フラグメンテーション(H11-1K-18)
可変長のときに使います。
|
すき間
|
|
///////
|
|
\\\\\\\
\\\\\\\
|
|
すき間
|
|
///////
|
図 メモリ分布
これらのすき間を集めて(カーベジコレクション)、メモリを確保します。
ロードされているプログラムの場所を変えることを”再配置”といいました。
☆ プログラム制御とシステムコール
再配置といえば、定番の『再○○』4つを復習しましょう。
|
再配置
|
リロケータブル
|
ロードされているプログラムの場所を変えること
|
|
再入
|
リエントラント
|
実行中に別タスクが同一プログラムを実行
|
|
再使用
|
リユーザブル
|
実行終了後、もう一度使用する
|
|
再帰
|
リカーシブル
|
自分自身をCALL
|
☆ ANSI/SPARCの3層スキーマ論(H11-1K-18)
|
|
|
論理データモデル
(それだけの相手
に見せますか?)
|
|
|
抽象化
|
↑
|
|
抽象世界
|
----→
|
概念データモデル
(これは、架空のモデルです)
|
|
|
|
↓
|
|
|
|
物理データモデル
(コンピュータに格納する
方法は?)
|
これを、ドキュメント化することをスキーマといいます。
|
ANSI・SPARCの
3層スキーマ
|
{
|
論理データモデル
|
・・・外部スキーマ
(Viewはこれです)
プログラムを組んだりします。
人が使います。
|
|
概念データモデル
|
・・・概念スキーマ
(DBMSに依存しません)
|
|
物理データモデル
|
・・・内部スキーマ
|
それぞれのスキーマは互いに独立しあっています。
(コンピュータに格納する方法が変わっても、Viewは変わらないし、その逆もない。)
これをそれぞれ、論理データ独立、物理データ独立と言います。
☆ データベース構造のモデル
データ構造モデルとして、次の3つとその特徴を覚えておきましょう。
|
階層モデル
|
親子関係
|
1:n
|
|
ネットワークモデル
|
n:n
|
|
関係モデル
|
|
|
☆ データベース言語
SQLの利用形態
SQLはデータ定義文(DDL)とデータ操作文(DML)で構成される。
データ操作文(DML)(H11-1K-45)(H10-1K-46)
|
構文
|
意味
|
内容
|
別の言い方
|
|
selection
|
選択
|
行を選ぶ
|
タプル、row
|
|
projection
|
射影
|
列を選ぶ
|
アトリビュート、カラム
|
|
join
|
結合
|
|
|
操作の順番として、
①自然結合(join)
②③ 選択(selection)、射影(projection)
で行います。
データ定義文(DDL)
これは、DDLの言葉だけ覚えておきましょう。
プログラム方式
埋め込み型言語・・・親言語(ホスト)がいて、その中にモジュールを埋め込む。
そして、モジュールごと呼ぶ(CALL ○○)
独立言語 ・・・ データベース独自が持っている言語(NAFRAL、T-SQL、PL/SQL)
☆ データベースの管理機能
データベースには次の管理機能を持っています。
再構成・・・構成を変更する
再編成・・・入出力を繰り返すうちに、データの物理的な並び方が乱れてきます。
すると、効率が悪くなるので、きれいに並びなおしてあげます。(H12-1K-48)
☆ 排他制御(ロック)
キーワードは”ロックする”です。
占有ロックと共有ロックの関係はこんなんでした。(H8-1K-54)
ロックの単位(これを粒度といいます)は、
|
|
これも覚えておきましょう
|
|
ロックの単位
|
粒度
|
同時実行性
|
オーバヘッド
|
排他待ち
|
|
DB全体
|
大
|
悪
|
小
|
大
|
|
テーブル単位
|
↑
↓
|
↑
↓
|
↑
↓
|
↑
↓
|
|
ページ単位
|
|
レコード単位
|
小
|
良
|
大
|
小
|
デッドロック(H12-1K-26)(H11-1K-21)(H11-1K-18)
|
|
X
|
|
Y
|
|
資源a
|
・
|
|
・
|
|
|
|
|
×
|
|
|
|
資源b
|
・
|
|
・
|
タスクXが資源aを確保し、タスクYが資源bを確保した後に、
タスクYが資源bを要求し、タスクYが資源bを要求すると、デッドロックが発生します。
対策としては、
ロックする順序を決めておきましょう。 (Xの後にYをロックするなど。)
デッドロックが起きてしまったら、DBMSが適切に対処します(一方をキャンセルします)
2相ロック
排他制御のところで、時々”2相ロック”という言葉が出てきます。
2相ロックとは、
・.データにアクセスする前にロックしなければならない。
・.トランザクション内で1度でもアンロック操作を行った場合、それ以降ロック操作は行わない。
(アンロックのみ)
です。
2相というのは、ロック獲得相と、アンロック相があるということです。
(2相コミットとは別の話です)
☆ トランザクション
1つの不可分な処理のかたまり。
例えば、
A・・・出荷する。
B・・・出荷した分、在庫を減らす。
このA,Bを合わせて、トランザクションといいます。
A,B,CのJOBがあって、A、Bは実行、Cは未実行・・・これはあってはなりません。
トランザクションはALL OR NOTHING です。
これをトランザクションの原子性(Atomicity)と言います。
トランザクションの性質として、ACIDを言う言葉がありました。(H11-1K-18)
|
A
|
Atomicity
|
原子性
|
All or Nothing。 これ以上分けられないこと
|
|
C
|
Concurrency
|
一貫性、同時性
|
矛盾の無いこと
|
|
I
|
Isolation
|
独立性、隔離性
|
どんな順序でも、同じ結果になること
|
|
D
|
Durability
|
耐久性
|
完結したトランザクションはDB障害で失われないこと
|
これでよく出てくるのが(A)です。
---①OK---②OK---③OK---コミット発行-→完了
①が終了、②が終了、③が終了でコミットを発行して完了します。
---①OK---②OK---③をしようと思ったけど、無理だった。
途中までで終わるということはありえないので、これは、なかったことにします。
←----------------
これをロールバックと言います。
☆ 障害対策(H11-1K-18)(H10-1K-49,50)
|
Backup
|
|
|
|
|
Check
Point
|
|
|
|
System
障害発生
|
|
|
|
①-->
|
Commit
|
|
|
|
|
⑤--->
|
Commit
|
|
|
|
|
|
|
|
②--->
|
Commit
|
|
|
|
|
⑦----
|
---
|
---× |
|
|
|
|
|
③--->
|
Commit
|
|
|
|
|
|
|
|
|
|
|
|
|
④----
|
------
|
--+->
|
Commit
|
|
|
|
|
|
|
|
|
|
|
⑥----
|
--+--
|
------
|
------
|
---
|
---× |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
定期的(例えば毎週金曜日19:00)に、
磁気ディスクなどにコピーする |
Check Pointで、バッファ(メモリ)中の
情報をDBに書き出す |
①、②、③はちゃんとトランザクションがコミットされていて、ハードディスクに書かれた状態です。
なので、何もする必要はありません。
それ以外の復旧方法
DBがダウンすると、ウォームスタートします。
チェックポイントまで戻って、そこから動き出します。
DBには、必ずDB以外にログというものがあります。
ログには更新履歴があります。それには、2つありましたね?
更新前情報と、更新後情報です。
④はコミットが終わっています。でも、チェックポイント後なので、その情報はなくなっています。
しかし、トランザクションは終了してるわけですから、それは、死守しないといけません。(ACIDのD)
対策)
一回実行前の状態に戻して(更新前情報でロールバック)、再度実行します。(更新後情報を使ってロールフォワード)
⑤は単にロールフォワードします。
⑥はロールバックして、必要なら再実行(Rerun)します。
⑦はRerunします。
☆ 2相コミット
|
|
主サイト |
|
|
|
|
|
|
|
DB-A
○--
完了 |
commit |
<-------|
| |
|
|
|
| commit
|-------->
↓ |
DB-B
---○
NG
|
分散DBでコミットしようと思ってAはOKだけど、Bはダメ・・・これは都合が悪いです。
だから、プレコミットをあらかじめ出して、全てからOKが来たら本格的にコミットを出します。
これを2相コミットと言います。
しかし、2相コミットだからといってかならずOKというわけではありません。
(プレコミットの後にDBが壊れることもあります。)
・「プレコミットOK」から実際にコミットが来るまでを”セキュア状態”と言います。
・プレコミット時、1つでもNGのDBサイトがあれば、ロールバックします。
☆ DBコピー(レプリケーション)(H11-1K-18)
東京から大阪にDBをコピーすることがよくあります。
DB1サイトが更新されました。
一定時間後(非同期に)DB2サイトにコピーします。
これをレプリケーションと言います。
☆ テーブルについて
○候補キー ・・・ 候補キーにされた列の値を決めると、行がユニークに定まります。
○主キー ・・・ 候補キーの中から、1つ選択したもの。
○外部キー ・・・ どこかの別のテーブルの主キー。
|
外部キー ←
|
--→
|
(どこかのテーブルの)
主キー
|
|
|
|
|
よくあるのが
|
外部キー ←
|
--→
|
(どこかのテーブルの)
主キー
|
|
|
|
|
○参照制約(H11-1K-18)
外部キーといえば、参照制約というのがあります。
商品マスタに004がないのに、売上表に追加することは出来ません。
逆に、売上表に001がいるのに、商品マスタの001を消してもいけません。
☆ 正規化(H11-1K-18)(H11-1K-44)(H10-1K-47)
定義
第1正規形にする ・・・ 1つのセル(箱)には1つのデータ。
同じ行の無いこと。
第2正規形にする ・・・ 部分関数従属の排除
第3正規形にする ・・・ 推移的関数従属の排除
なぜ、正規化をするのか?
→ 冗長性の排除です。
|
名前
|
塾コース
|
塾コース略称
|
|
KIKI
|
ネットワーク
|
NSP
|
|
Harry.
|
ネットワーク
|
NSP
|
|
真夏
|
ネットワーク
|
NSP
|
上表では、ネットワーク-NSPと同じデータが3つあります。
ここで、NSPをTE(NW)に変える時も変え忘れが起こる時があります。
練習問題1(正規化)
|
社員コード
|
社員名
|
所属コード
|
所属名
|
資格コード
|
資格名
|
上表が第1正規形になっているものとして、最終的に第3正規形にして下さい。
(仮定)・複数の部署に所属することは無い。
・資格はいくつ持っててもかまいません
①主キーを探す。
主キー ・・・ 1つ決まれば、行全体が決まります。
→ 社員コードと資格コードが決まれば、この長い列全てが決まりますよね。
|
社員コード
|
社員名
|
所属コード
|
所属名
|
資格コード
|
資格名
|
②部分関数従属の排除
部分関数 ・・・ 1つ決まれば相手が決まる関係。(xが決まればyが決まる感じ)
部分とは、主キーのことです。
今回の主キーは社員コードと資格コードです。
それが決まれば、決まるものがあります。
社員コード → 社員名、所属コード、所属名
資格コード → 資格名
③推移的関数従属の排除
推移的関数 ・・・ xが決まればyが決まる
yが決まればzが決まる ・・・この推移のこと。
社員コードが決まれば、所属コードが決まります。所属コードが決まれば、所属名が決まります。
最終的には、、、
練習問題2(自己結合)
T1
|
No.
|
Name
|
Age
|
Leader
|
|
1
|
田中
|
40
|
2
|
|
2
|
鈴木
|
30
|
2
|
SELECT X.Name
FROM T1 X , T1 Y
WHERE X.Leader = Y.No AND X.Age > Y.Age
何が答えでしょう?
自分同士ひっつけるので、見分けがつかないので片方をX、もう片方をYとしましょう。
X.NO1に対して、Y.NO1とY.NO2、X.NO2に対して、Y.NO1とY.NO2があります。
とりあえず引っ付けてみましょう。
|
|
X.No.
|
X.Name
|
X.Age
|
X.Leader
|
|
Y.No.
|
Y.Name
|
Y.Age
|
Y.Leader
|
|
(A)
|
1
|
田中
|
40
|
2
|
|
1
|
田中
|
40
|
2
|
|
(B)
|
1
|
田中
|
40
|
2
|
|
2
|
鈴木
|
30
|
2
|
|
(C)
|
2
|
鈴木
|
30
|
2
|
|
1
|
田中
|
40
|
2
|
|
(D)
|
2
|
鈴木
|
30
|
2
|
|
2
|
鈴木
|
30
|
2
|
これの作業を自然結合といいます。
そのあとに、選択、射影です(と書きました →ジャンプ)
X.Nameを選択します。
まず、
X.Leader = Y.No ・・・ (B)と(D)です。(射影1)
X.Age > Y.Age ・・・ (B) です (射影2)
→ 田中さんですね。
☆ プロセスモデル(H11-1K-18)(H10-1K-60)
プロセスモデルプログラムを作っていく時の話でした。
「分析」→「計画」→「設計」→「開発」→「テスト」・・・・
そのモデルには次のようなものがありました。
・ウォータフォールモデル
・成長モデル
・スパイラルモデル
・プロトタイプモデル
それぞれの特長は
・ウォータフォールモデル
・後戻りなし(後工程ほど、後戻り工数が大きい)
・フェーズ(段階)に分けて開発
・次のフェーズに入る前にチェックする
・大規模向け
・工数が管理しやすい
・成長モデル
・分析、開発、チェック・・・・を繰り返す手法
・仕様変更、改良向け
・スパイラルモデル
・独立性の高いサブシステムに分割、開発。
(成長モデルと、スパイラルモデルの住み分けが難しい)
・プロトタイプモデル
・試作品を作って、外部仕様を決定する。
・手戻り作業の防止
☆ RAD (Rapid Application Development)ツール
専門のツールを使って、短期間で作ってしまいましょう!というものです。
キーワードは、
・タイムボックス(限られた時間の中で)
・ツールを使う
・少数精鋭
・短期間
☆ コストモデル
ソフトウエア工学で、プロセスモデルともう一つのモデルといえば、コストモデルです。
コストモデルはこの2つを覚えておきましょう。
・ファンクションポイント(FP)法(H11-1K-18)
入出力インターフェース、画素数、ファイル数、帳票数 × 複雑さの度合い(係数)
・COCOMO(コンストラクションコストモデル)法(H11-1K-18)
いわゆる工数(○○人月で△△円)
開発ステップ数、難易度も要因となります。
個人の能力に左右されます。
・開発規模と工数の関係
|
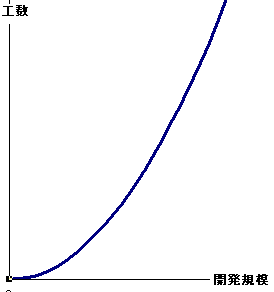
|
開発規模と、工数の関係は比例ではありません。
規模が大きくなると、管理なども複雑になって、
リニアにはいかないです。 |
☆ モデル図(H11-1K-18)(H11-1K-64)
・E-R図(H11-1K-18)
・DFD
・ペトリネット図
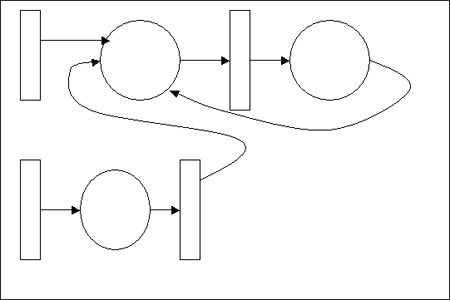
あと、状態遷移図もあります。
☆モジュール設計
これでプログラム設計が終わったので、次はモジュール設計をします。
モジュール分割(H10-1K-62)
その分割方法にも種類があります。
①STS分割 Source(源泉) 、 Transform(変換) 、 Sink(吸収)
|
入力
データ
|
|
変換
データ1
|
|
変換
データ2
|
|
出力
データ
|
|
------>
|
(機能1)
|
------->
|
(機能2)
|
-------->
|
(機能3)
|
----->
|
|
|
|
↑
|
|
↑
|
|
|
|
|
|
最大抽象
入力点
|
|
最大抽象
出力点
|
|
|
|
<------
|
源泉(S)
|
--->|<---
|
変換(T)
|
--->|<---
|
吸収(S)
|
----->
|
|
元の形があるところ
|
変換途中のところ
|
アウトプットの形が
見えてきたところ
|
②TR分割 (トランザクション分割)
ほとんどが、STSでうまく分かれません。
トランザクションごとに分けてみましょうという方法です。
③共通機能分割
共通の機能だけ分けてみましょうという方法です。
④データ構造からの分割
ジャクソン法・・・入出力データ
ワーニエ法・・・出力データ
どっちが入出力データで、どっちが出力データだけだったか覚えておきましょう。
モジュール強度とモジュール結合度(H11-1K-63)
モジュール分割と言えば定番の問題が、これでした。
試験対策としては、強い方がいいのか?弱い方がいいのか?と、
その両端を覚えておきましょう。
モジュール強度(強い方がいい)(H10-1K-63)
|
強
↑
|
|
|
|
|
↓
弱
|
機能的強度
|
|
情報的強度
|
|
連絡的強度
|
|
手順的強度
|
|
時間的強度
|
|
論理的強度
|
|
暗号的強度
|
(昨日の常連ってチロリアン)
機能的強度のキーワード・・・単機能、1モジュール、1ステップ
モジュール結合度(弱いほどいい)
|
弱
↑
|
|
|
|
|
↓
強
|
データ結合
|
|
スタンプ結合
|
|
制御結合
|
|
外部結合
|
|
共有結合
|
|
内部結合
|
(出たスター選手が今日いない)
データ結合のキーワード・・・構造をもたない、引数でモジュール間のデータを引渡しする。
☆DOA(データ中心アプローチ)
要はデータ中心に考えるのです。
特長
・データは変わりにくい
その変わりにくいデータを中心に考えて物事を処理しましょう。
・プロセスは変わりやすい。
・データの重複を防ぐ
プロセスの重複も当然防ぎます。
☆オブジェクト指向(H11-1K-18)(H11-1K-62)(H10-1K-61)
カプセル化(データ+手続き(メソッド))
”このデータを使うには、この手続きをしないといけないですよ”ということです。
例えば、年齢というデータで考えてみましょう。
年齢という数字に、自由な整数が入っても困ります。
まず、0以上で150以下の数字ならOK!
という手続きをふみます。
インスタンス(実体)
(オブジェクト) <---メッセージ--- (オブジェクト)
オブジェクト間はメッセージでやりとりします。
インヘリタンス(継承)
ヒトというクラスがあるとします。(属性:年齢)
ポリスはヒトですから、ヒトクラスを使ってポリスクラスを定義します。(属性:年齢、階級)
年齢の属性は継承されます。
集約と分解 (part-of関係)
|
|
|
(パソコン)
|
|
|
親クラス(スーパクラス)
|
|
|
/
|
|
|
\
|
|
|
|
(CRT)
|
|
(CPU)
|
|
(KB)
|
子クラス(サブクラス
|
汎化と特化 (is-a関係)(H11-1K-43)
|
|
|
(車)
|
|
|
親クラス(スーパクラス)
|
|
|
/
|
|
|
\
|
|
|
|
(トラック)
|
|
(バス)
|
|
(RV)
|
子クラス(サブクラス
|
☆プログラムのテスト
コーディングのあとに、テストをします。
・追加型テスト
トップダウンテスト・・・スタブが必要です。
ボトムアップテスト・・・ドライバが必要です。
ブラックボックステスト・・・同値分割(結果が同じになるグループに分けて、テストデータに投入)
(functionに注目) 限界値分析(仕様に基づいて入力データの限界値をテストデータに投入)
(H12-1K-65)(H11-1K-65)(H10-1K-65,66)
ホワイトボックステスト・・・○○網羅(自分が作った命令がテストでどれくらい実行されたか?)
(Codeに注目)
非増加型テスト(一気にボン!)
一斉テスト
ビックバンテスト(単体テストのみ済み)
☆ソフトウエアの品質管理
レビュー方式
資料を事前に配布しておきましょう
ウォークスルー(ローカルチェック)(H10-1K-67)
非公式
管理職NG
持ち回り(プログラム開発者が座長)
インスペクション(大掛かりなやつ)
公式
ドキュメント化
フォローアップあり
モデレータ(司会者)
信頼性予測方式
信頼性成長曲線モデル(H11-1K-68)
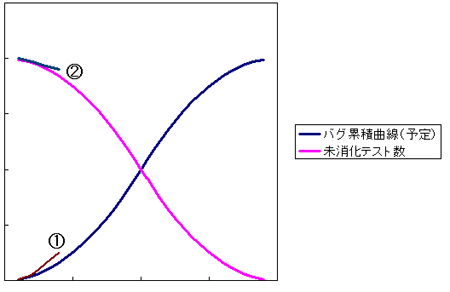
時間を進めると、テストを消化し、発見したバグが増えていきます。
結果、①前工程の品質悪いし、
②バグつぶしに時間が掛かっている
※このモデルを使った出題では、”OKなので、どんどん行きましょう!”というのは、
ありません。
☆その他ソフトウエア関連でよく出る変な問題
ISO 9000-3(キーワードのみ)
・ソフトウエア品質保証
・作る側、買う側の契約(シュリンクラップ製品は除く)
・設計~保守・付帯サービスまで
・管理的な側面を重視(ドキュメント)
・プロセスモデル非依存
開発したソフトウエアの著作権(H12-1K-73,74)(H11-1K-72)
キーワードは派遣か、請負か?
特許
|
|
著作権
|
特許
|
|
出願
|
不要
|
要
|
|
有効期限
|
著作者の死後50年
|
出願から20年
|